Previously on Factorio Friday Facts (#264): "No wonder, scenes heavy on smoke or trees can tank FPS, especially in 4K. Maybe we should do something about that..."
Writing technical Friday Facts helps me to summarize what I know, look at problems from a different perspective, and sometimes try to answer questions I haven't even thought of asking before.
For example, I made the overdraw visualization just for screenshot for FFF-264, and while writing the FFF I didn't analyze them. Just after the blog post was released I looked at it and started thinking - why does smoke create such a huge overdraw blob when it is just barely noticeable in game view? Well, it turned out it was largely due to a bug. Some time ago we optimized smoke particles so that they are only updated once every 120 ticks (2 seconds), and its animation (movement, scale and opacity) is interpolated during drawing.
Thing is, particles are destroyed only during their update, if the lifetime of a particle ended somewhere in middle of the 120 tick window, the particle would be still drawn until destroyed. Because smoke fades away and scales up during its lifetime, it would be drawing itself fully transparent over a large area. Making the smoke particle not draw itself past its lifetime reduced number of particles being drawn by 15%, and reduced the number of pixels being rasterized even more. Additionally, particles below 2% opacity don't really seem to add anything to the final picture, so we can safely not draw those to get little extra boost.
Probably only a very small number of our players actually run into this issue during normal play, but it is simple problem that we used to learn more about how to use GPUs more efficiently.
Turret ranges in the map view are rendered as opaque geometry (no sprites) to an offscreen buffer which is subsequently drawn semi-transparently to the game view. This makes the turret ranges blend into single solid shape of the same color. Every pixel is written for each turret in range, but if it is written once, subsequent writes are unnecessary.
We had two ideas how to optimize this. First, enable stencil test, so that pixels can be written just once. The second, pass a list of turrets to the GPU and test if each pixel is in range of any turret using a pixel shader. The stencil test idea yielded about 3x speed-up in our extreme test cases (20x20 turrets) which was not good enough - if your GPU had a problem with 3x3 grid, it would have problem again with 9x3 grid, which is not such a preposterous setup to have. The pixel shader idea turned out to be mixed bag - if the entire screen was in range, the shader would be lightning fast, but as soon as there were pixels outside of range, which meant shader had to iterate through entire list of turrets to figure out none covers it, performance started to drop off rapidly. In the worst case, it would be worse than without optimization.
Jiri came up with idea to do prepass, in which we would render the geometry into a much smaller buffer (let's say 16x smaller in both width and height) and then in turret range shader we would check if a pixel is definitely in range (pixel in prepass buffer is fully opaque), definitely out of range (pixel in prepass buffer is fully transparent) or we don't know (pixel in prepass buffer is semi-transparent due to linear filtering) and we need to the pixel against the turret list. He did that and performance improved slightly, but not as much as we hoped for. After further investigation we found out the GPU really doesn't like the early exit in the pixel shader. Jiri managed to remove it by rendering all the certain cases first, while marking uncertain pixels in stencil buffer, and in another pass he would run the turret range shader on just stenciled pixels. This solution ended up being up to 20x faster in cases that were too slow with the un-optimized solution, but as you would zoom out more and there were more turrets covering less pixels on screen, the orginal solution would become better. So we turn on the optimization only when you are zoomed in enough.
By the way, artillery ranges suffered from the same problem in early 0.16 versions, but they are so large it was good enough for us to test if entire screen is in range, and draw just single fullscreen rectangle in that case. Turrets were very likely to cause problems on low-end GPU even when not covering the entire screen.
As always, the root of all performance degradation is memory access. Since we mostly do just simple sprite drawing, the GPU has to read pixels from a texture, and blend it into a framebuffer. Which technically means reading pixels from another texture, doing some simple maths with the two values, and writing the result back. GPUs are designed to do this on a massively parallel scale and are optimized for high memory bandwidth while sacrificing memory latency. The assumption is you'll want to do at least a little bit of maths on the colors that you fetch from textures, to give the resulting image some dynamic detail. Every GPU core can then have many scheduled tasks and switch between them as the current task starts waiting on some memory operation to finish.
When you don't really do any math to add dynamic details, and all detail comes from drawing more layers of sprites, the GPU cores quickly reach their limit of maximum tasks and every one of them is stalled by a memory access. That is not to say we don't hit memory bandwidth limits on some hardware. For cases where we do hit memory bandwidth limits, we added an option to do rendering in 16-bit color depth (as opposed to the normal 32-bit). This option is intended for old GPUs and integrated GPUs.
An obvious way to improve this is to shade less pixels. This is something I mentioned before in FFF-227 by splitting tree shadows from tree trunks to remove large areas of completely transparent pixels. This can be improved further by drawing sprites not as rectangles but as generic polygons that envelope sprites such that most of the fully transparent areas won't be rasterized. This is something we will probably do for the most problematic sprites (trees and decoratives).
Another way to reduce the number of shaded pixels is to simply to render in lower resolution. We actually do this for lights for a long time already, but it could be used for other effects that don't have important high frequency detail - for example smoke. Ultimately, some GPUs are not cut for rendering the game in FullHD resolution no matter what (for example Intel HD Graphics 2500 or multimedia cards like GeForce GT 710 and Radeon HD 6450 come to mind), so they would benefit from an option to render the game view in lower resolution with native-resolution GUI overlay.
In FFF-227, I also mentioned mipmaps - downscaled copies of textures that are used when a texture is being scaled down. This helps to better utilize the caches on GPU, and therefore reduce the need to access main VRAM. We already used mipmaps for trees and decoratives in 0.16, but paradoxically some people had performance issues when they had mipmaps enabled. The problem is, in 0.16 we always use trilinear filtering for mipmapped textures. That means when you want to draw as sprite at 75% scale, the GPU will get a pixel from the 100% scale mipmap, and the 50% scale mipmap and average them to get the pixel for the 75% scale version. The access to two different mipmap levels would make things slower. In the new rendering code, we are able to control this, so for sprites that are likely to cause performance issues (for example smoke) we can just fetch pixels from the closest finer detailed mipmap.
GPUs natively support block compressed formats - the texture is divided into 4x4 pixels (or possibly different sizes in formats that are not commonly supported by desktop GPUs) and each block is compressed into a fixed number of bytes. Commonly supported formats on desktop GPUs are BC1-7. Most interesting to us, are:
These formats work pretty well with normal textures, but not so well with 2D art that contains a lot of small detail. With our art it is not so bad as long as sprites are static, but as soon as we apply the compression on animations, even tiny changes in individual pixels results in larger changes in blocks that contain them, and the resulting animation ends up looking very noisy.
Uncompressed vs. BC3 compression
Awesomenauts developers described this in their blogpost on how compressed formats supported by GPUs work, what kind of artifacts it creates in their art, and what they do to improve quality. They store their sprites in a slightly higher resolution (for example 41% larger width and height) to spread the large frequency detail more apart. This makes compression less efficient but still worth it. The problem is, we can't really do this as it makes our sprites look pretty bad and blurry.
During our initial experiments with compression, we deemed the quality of compression to be too low. In addition to that it somewhat slowed down the game startup as we built sprite atlases in an uncompressed format first and compressed them at the end of the sprite loading process. I left the 'Texture compression' option in, for people who really needed to use it, and it would compress only the sprites that usually blend over some other graphics (like color masks, shadows and smoke).
The most commonly used image or video compression formats (like JPEG or H.264) exploit the fact that human vision is actually pretty bad at recognizing colors and is much more sensitive to changes in brightness. Instead of RGB color space they use of color space based on luma (brightness) and chrominance (color), and apply better quality compression to the luma component and lower quality to color components, resulting in a very high quality image to the human eye. Some smart people thought this technique could be used to improve the quality of GPU block compression formats.
One of the ideas is YCoCg-DXT compression which uses BC3 as an underlying format and stores luma in alpha channel for higher quality compression and chrominance in RGB channels. Pixel shaders that use these textures need to do just a little bit of math to convert colors from YCoCg color space to RGB. We tried to integrate this (using separate BC4 compressed texture for alpha channel) and were pleasantly surprised by the result. You probably won't notice artifacts unless you zoom-in a lot and look for them. In fact, two weeks ago I enabled texture compression by default (and didn't tell anyone), and whenever I ask somebody on the team if they disabled it, they say they didn't know it was turned on. So I am pretty happy about that. The small downside is the need to use two textures (BC3 + BC4) resulting in 12 bits per pixel, but the best thing is, despite the pixel shader having to fetch from 2 textures instead of just one, the GPU is able to render up to twice as fast due to caches being able to fit more pixels in compressed formats than in raw formats.
Luckily the paper contains the pixel shader code for compressing to this format on GPU, so we just had to adapt our sprite loading code to efficiently utilize GPU for compressing sprites as they are being loaded, so that the fact that we are compressing sprites during startup doesn't make the game load slower.
In 0.17, the texture compression graphics setting is changed to a drop down list containing 'None', 'High quality' and 'Low quality':
Uncompressed vs. High quality compression vs. Low quality compression
After we added the high-res worms, biters, and spitters, VRAM usage rose up to 3.5GB (with high-res enabled, obviously) when no compression (even the shadow one) was applied. Compressing just shadows decreased VRAM usage to 0.16 levels of ~2.5GB. With high quality compression enabled, VRAM usage of sprite atlases currently is ~1GB (without mipmaps). This means, vanilla should be perfectly playable in high-res on GPUs with 2GB VRAM, and in combination with texture streaming these GPUs should be able to keep up in high-res even in cases when mods add a lot of new sprites. High-resolution sprites were originally intended for players with the most powerful computers, but in 0.17, they'll essentially become new standard. The goal is to eventually remove the 'low' and 'very-low' sprite resolution options, as 'low quality' texture compression on normal sprites + texture streaming should be able to run even on GPUs with very low VRAM sizes.
Side note: I mentioned there are 7 BC formats. BC7 is intended for RGB or RGBA textures, and has potentially much better quality than BC3 with the same compression ratio. The problem is, the format was introduced with DirectX 11, so it is not supported by DirectX 10 class hardware, and it is not available in OpenGL on macOS. The second problem is that it takes a very very long to compress something into this format, because the compressor has to try out a large number of configurations for each block to find the one that yields the best quality. Since Factorio is kind of outlier in that its art is distributed in bunch of PNG files instead of having everything neatly packaged so that graphical assets can be loaded directly to the GPU, without any transcoding to a different format or dynamically building sprite atlases, we require a real-time compression solution. We are not eager to change how the game is distributed too much, for one having everything in separate files makes updates reasonably small when we change some of them, and having vanilla data completely open makes it easier for people to mod the game.
We took some benchmarks of extreme scenes. The first one is on save from public Clusterio event last year. Twinsen sent me the save, because he was getting framerate drops in the middle of large steam turbine array. The second one is save from a bug report. I choose the save because it has rails going though forest and because I could really get low FPS on it even in 0.16, I used map editor to carpet the ground with grass decoratives.
We tested on GPUs with 2GB or 1GB of VRAM, that we have in the office. Benchmarks on desktop GPUs ran on single PC (we just swapped GPUs between runs) - Intel Core i7-4790K, 16GB RAM, Windows 10. We measured the time a frame was being processed by GPU, for 1000 frames, and averaged out the results. We benchmarked against the 0.17 build from before GPU-side optimizations were implemented, unfortunately we don't have a way to capture GPU timings in 0.16. Tests ran in FullHD resolution (1920x1080) with high resolution sprites enabled, with a graphic configuration that I believe to be the best for rendering performance. For old build: Mipmaps, Atlas specialization, Separate lower object atlas, Texture compression options enabled, Video Memory Usage set to All. And equivalent configuration for the new build, except for using the new high quality compression option.
We also included a result from one high-performance GPU (GeForce GTX 980 4GB), but this was ran in 4K resolution (3840x2160) as opposed to FullHD. The benchmark of Intel HD Graphics 5500 was ran on a laptop with Intel Core i7-5600U and 16GB RAM, and used Low quality texture compression instead. We also included results with 16-bit color depth enabled.

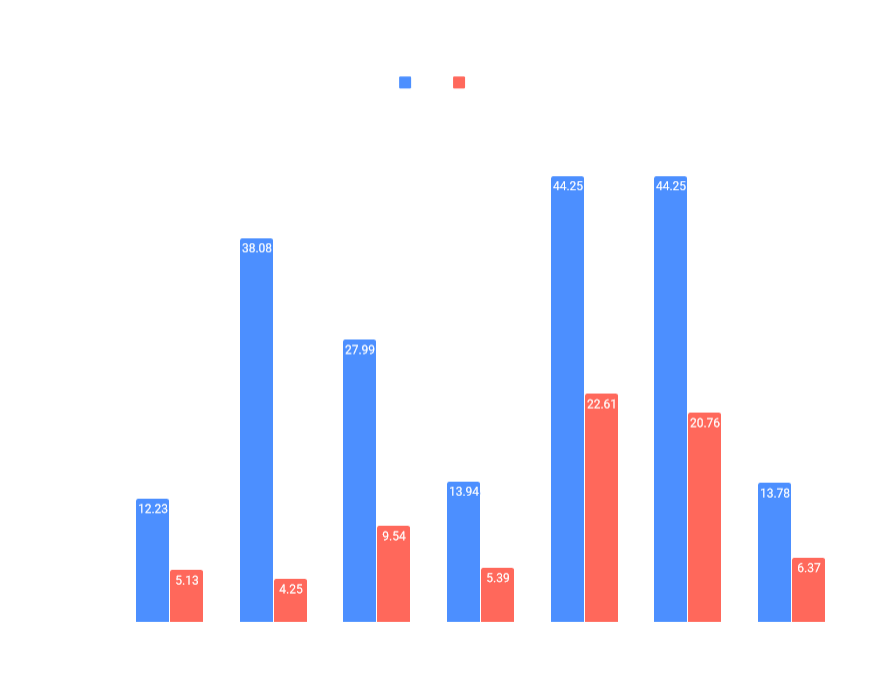

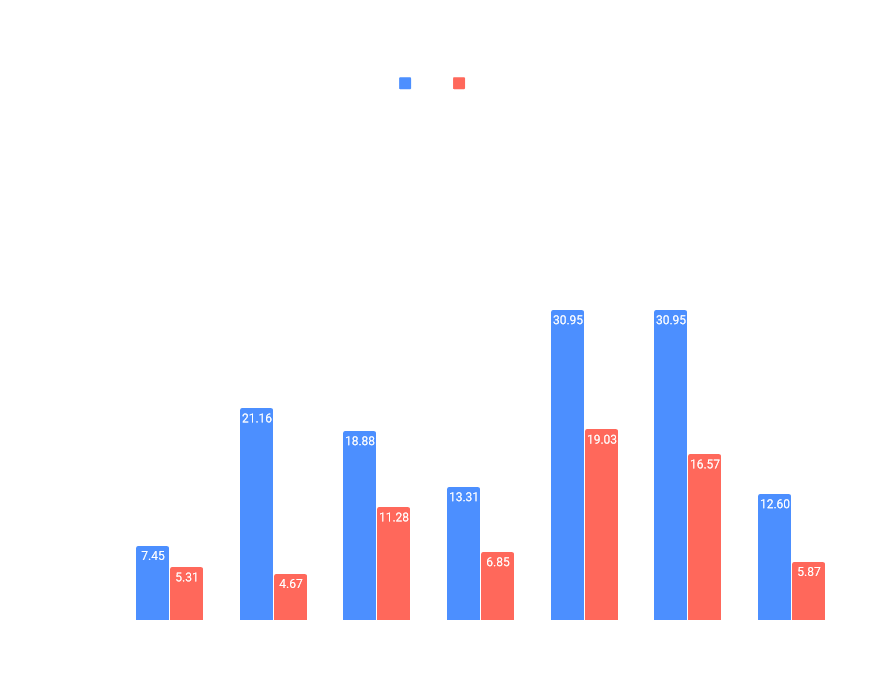
Times were measured in milliseconds. Lower times are better, and for 60 FPS, a frame needs to take under 16.66ms.
If you are interested in how GPUs work more in-depth, Fabian Giesen wrote a nice series of articles on the topic.
As always, let us know what you think on our forum.